AI Anarchies: Adversarial Acoustics
Workshop
An Introduction to Adversarial Acoustics
Instructors:
Murad Khan, Martin Disley

Profile:
Murad Khan
Murad Khan is a course leader and senior lecturer at UAL’s Creative Computing Institute. His research explores the relationship between pathology, perception and prediction across cognitive neuroscience and computer science, outlining a philosophy of noise and uncertainty in the development of predictive systems. He is a member of the collaborative research studio Unit Test, which explores the place of investigative methods in counter data-science practices.
Profile:
Martin Disley
Martin Disley is an artist, researcher and software developer at Edinburgh University. His visual practice centres around critical investigations into emerging data technologies, manifesting their internal contradictions and logical limitations in beguiling images, video and sound. He is a member of the collaborative research studio Unit Test, which explores the place of investigative methods in counter data-science practices.
Brief:
Through theoretical discussion and practical computing exercises, Autumn School participants will explore the legacy of vocal forensics, the use of the voice as a tool for profiling and measurement, and the use of voice in machine learning systems. Taking sound studies scholar Jonathan Sterne’s account of a ‘crip vocal technoscience’ as a starting point, the relationship between interiority and exteriority will be complicated, during the development of an adversarial approach to vocal acoustics.
Soundbite:
“The development of techniques for facial recognition models have reinvented the relationship between interior and exterior common to the pseudoscience of physiognomy and phrenology.”
Murad Khan & Martin Disley, on working back from notions of visual similarity to sonic similarity
Takeaway:
Modelling voices is difficult but not impossible. Khan & Disley’s suggested workflow is to start with airflow, then apply a filter (mimicking the manipulation of the oral cavity), then model the speech sound. Focusing on these three variables, it is possible to develop a model.
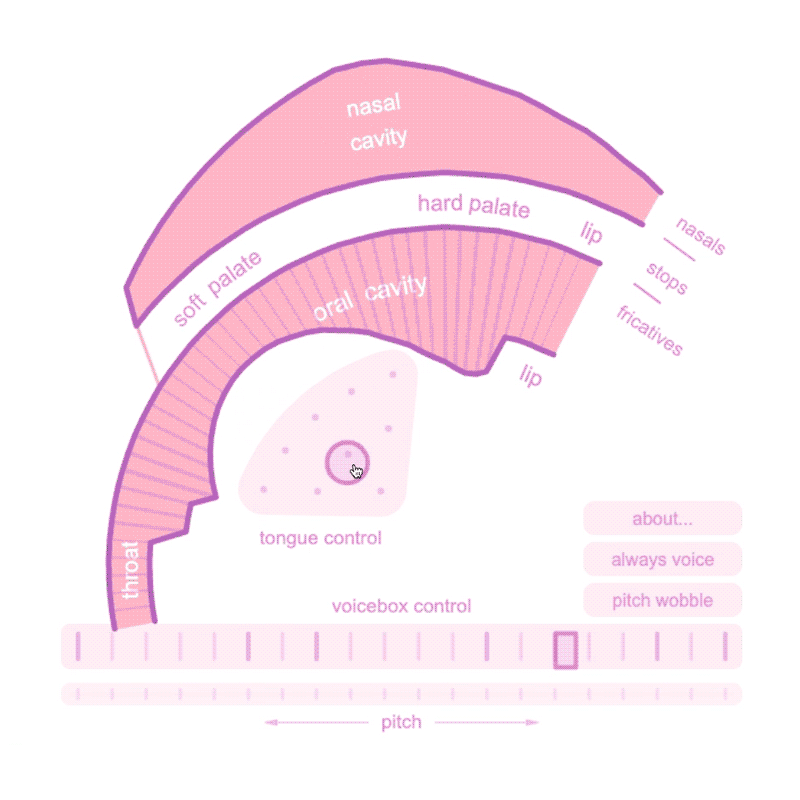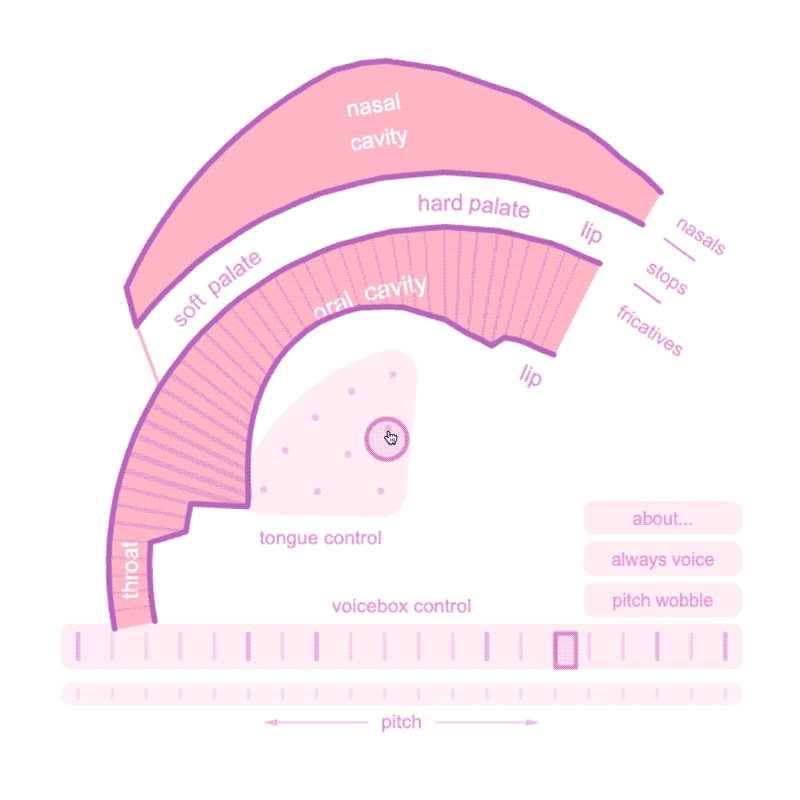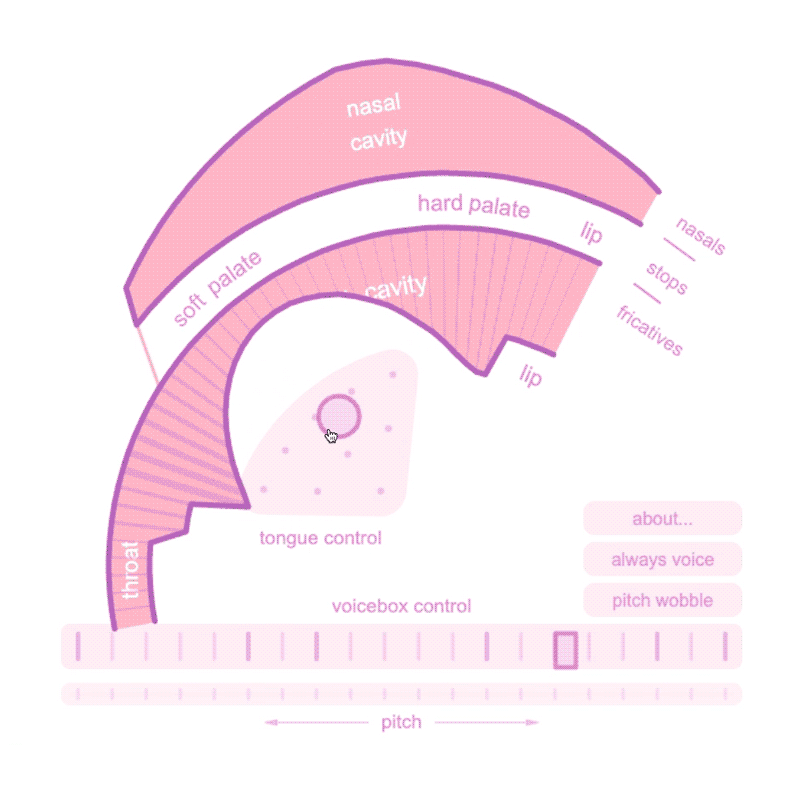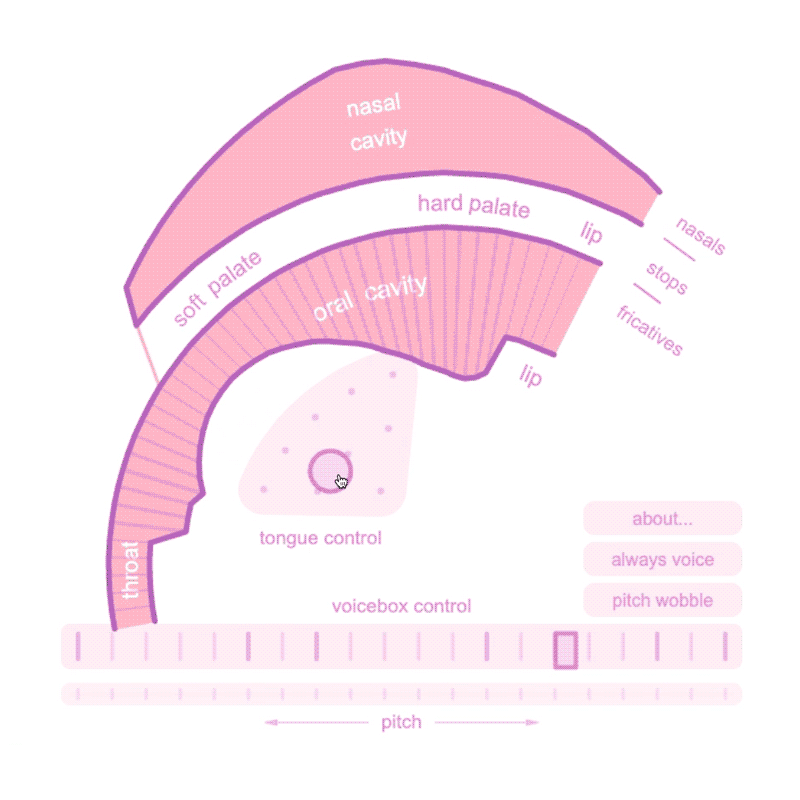
Precedent:
Demonstrating the complex physiology of speech with aplomb is Pink Trombone (2017), a web-based speech synthesizer by Neil Thapan that allows users to physically model speech sounds by modulating a simulated oral cavity, tongue, and voicebox. With its slightly unnerving continuous drone of “owwwwwwww,” a user quickly gets a sense of the enormous complexity of human speech.
Soundbite:
“Asking how a machine hears is really like asking how it sees.”
Murad Khan & Martin Disley,

Precedent:
Sound studies scholar Jonathan Sterne’s 2019 Journal of Interdisciplinary Vocal Studies article “Ballad of the dork-o-phone: Towards a crip vocal technoscience,” provides a key point of reference for the workshop. There, drawing on his highly personal relationship with the Spokeman Personal Voice Amplifier (which he calls the ‘dork-o-phone’) which he has used since a 2009 surgery, he carefully considers his relationship with his assistive technology, ultimately concluding “every speech act involving my voice raises anew the relationship between intent and expression, interiority and exteriority” (p.187).
Takeaway: